
Apple researchers have published a study about Manzano, a multimodal model that combines visual understanding and text-to-image generation, while significantly reducing performance and quality trade-offs of current implementations. Here are the details.
An interesting approach to a state-of-the-art problem
In the study titled MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer, a team of nearly 30 Apple researchers details a novel unified approach that enables both image understanding and text-to-image generation in a single multimodal model.
This is important because current unified multimodal models that support image generation often face trade-offs: they either sacrifice visual understanding to prioritize autoregressive image generation or prioritize understanding, sacrificing generative fidelity. In other words, they often struggle to excel at both simultaneously.
Here’s why that happens, according to the researchers:
A key reason for this gap is the conflicting nature of visual tokenization. Auto-regressive generation usually prefers discrete image tokens while understanding typically benefits from continuous embeddings. Many models adopt a dual-tokenizer strategy, using a semantic encoder for rich, continuous features while a separate quantized tokenizer like VQ-VAE handles generation. However, this forces the language model to process two different image token types, one from high-level semantic space versus one from low-level spatial space, creating a significant task conflict. While some solutions like Mixture-of-Transformers (MoT) can mitigate this by dedicating separate pathways for each task, they are parameter-inefficient and are often incompatible with modern Mixture-of-Experts (MoE) architectures. An alternative line of work bypasses this conflict by freezing a pre-trained multimodal LLM and connecting it to a diffusion decoder. While this preserves the understanding capability, it decouples generation, losing potential mutual benefits and limiting potential gains for generation from scaling the multimodal LLM.
Put simply, current multimodal architectures aren’t well-suited to performing both tasks simultaneously because they rely on conflicting visual representations for understanding and generation, which the same language model struggles to reconcile.
That’s where Manzano comes in. It unifies understanding and generation tasks by using an autoregressive LLM to predict what the image should contain semantically, then passes these predictions to a diffusion decoder (the denoising process we explained here) that renders the actual pixels.
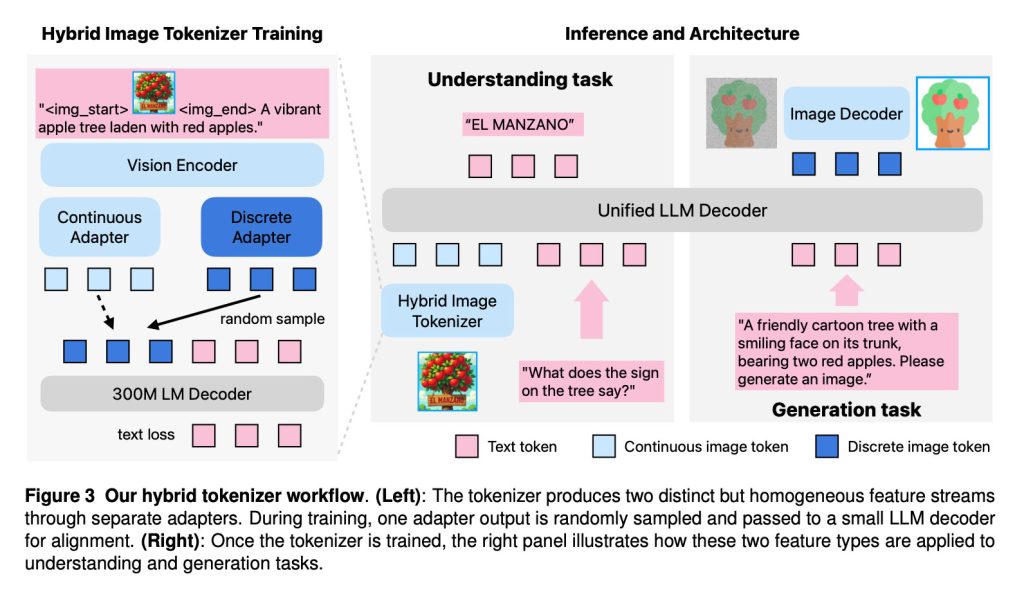
As the researchers explain, Manzano combines three components in its architecture:
- A hybrid vision tokenizer that produces both continuous and discrete visual representations;
- An LLM decoder that accepts text tokens and/or continuous image embeddings and auto-regressively predicts the next discrete image or text tokens from a joint vocabulary;
- An image decoder that renders image pixels from predicted image tokens
As a result of this approach, “Manzano handles counterintuitive, physics-defying prompts (e.g., ‘The bird is flying below the elephant’) comparably to GPT-4o and Nano Banana,” the researchers say.

The researchers also note that in multiple benchmarks, “Manzano 3B and 30B models achieve superior or competitive performance compared to other SOTA unified multimodal LLMs.”
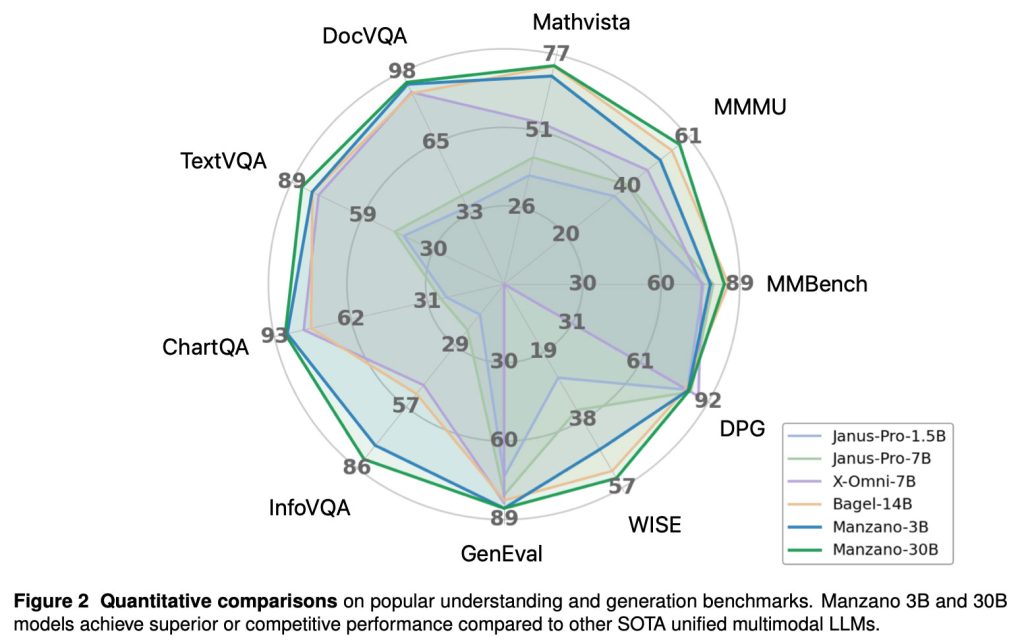
Apple’s researchers tested Manzano across several sizes, from a 300M-parameter model up to a 30B-parameter version. This allowed them to evaluate how unified multimodal performance improves as the model scales:

Here’s another comparison between Manzano and other state-of-the-art models, including Google’s Nano Banana and OpenAI’s GPT-4o:

Finally, Manzano also performs well in image editing tasks, including instruction-guided editing, style transfer, inpainting/outpainting, and depth estimation.

To read the full study, with in-depth technical details regarding Manzano’s hybrid tokenizer training, diffusion decoder design, scaling experiments, and human evaluations, follow this link.
And if you’re interested in this subject, be sure to check out our explainer on UniGen, yet another promising image model that Apple researchers have detailed recently. While none of these models are readily available on Apple devices, they suggest ongoing work toward stronger first-party image-generation results in Image Playground and beyond.
Accessory deals on Amazon
- AirPods Pro 3
- Beats USB-C to USB-C Woven Short Cable
- Wireless CarPlay adapter
- Logitech MX Master 4
- Apple AirTag 4 Pack
FTC: We use income earning auto affiliate links. More.


Comments