
Building on a previous model called UniGen, a team of Apple researchers is showcasing UniGen 1.5, a system that can handle image understanding, generation, and editing within a single model. Here are the details.
Building on the original UniGen
Last May, a team of Apple researchers published a study called UniGen: Enhanced Training & Test-Time Strategies for Unified Multimodal Understanding and Generation.
In that work, they introduced a unified multimodal large language model capable of both image understanding and image generation within a single system, rather than relying on separate models for each task.
Now, Apple has published a follow-up to this study, in a paper titled UniGen-1.5: Enhancing Image Generation and Editing through Reward Unification in Reinforcement Learning.
UniGen-1.5, explained
This new research extends UniGen by adding image editing capabilities to the model, still within a single unified framework, rather than splitting understanding, generation, and editing across different systems.
Unifying these capabilities in a single system is challenging because understanding and generating images require different approaches. However, the researchers argue that a unified model can leverage its understanding ability to improve generation performance.
According to them, one of the main challenges in image editing is that models often struggle to fully grasp complex editing instructions, especially when changes are subtle or highly specific.
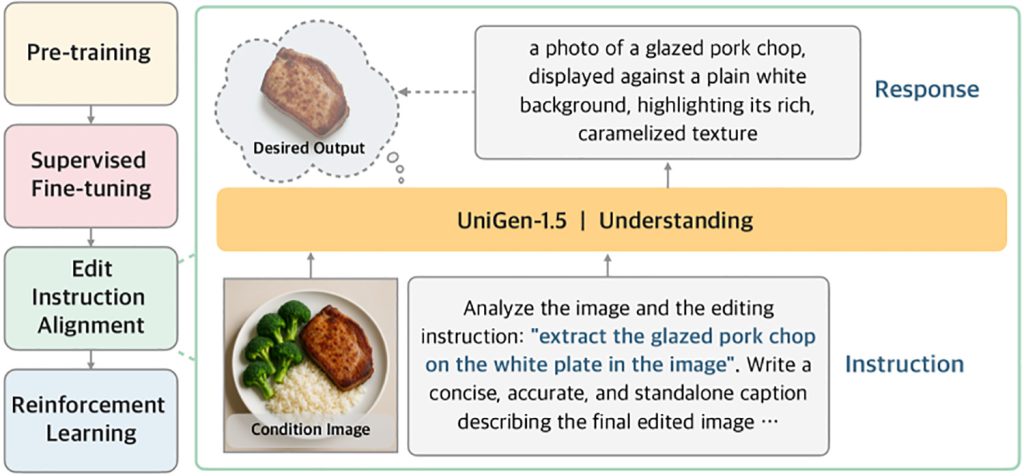
To address this, UniGen-1.5 introduces a new post-training step called Edit Instruction Alignment:
“Moreover, we observe that model remains inadequate in handling diverse editing scenarios after supervised fine-tuning due to its insufficient comprehension of the editing instructions. Therefore, we propose Edit Instruction Alignment as a light Post-SFT stage to enhance the alignment between editing instruction and the semantics of the target image. Specifically, it takes the condition image and the instruction as inputs and is optimized for predicting the semantic content of the target image via textual descriptions. Experimental results suggest that this stage is highly beneficial for boosting the editing performance.”
In other words, before asking the model to improve its outputs through reinforcement learning (which trains the model by rewarding better outputs and penalizing worse ones), the researchers first train it to infer a detailed textual description of what the edited image should contain, based on the original image and the editing instruction.
This intermediate step helps the model better internalize the intended edit before generating the final image.
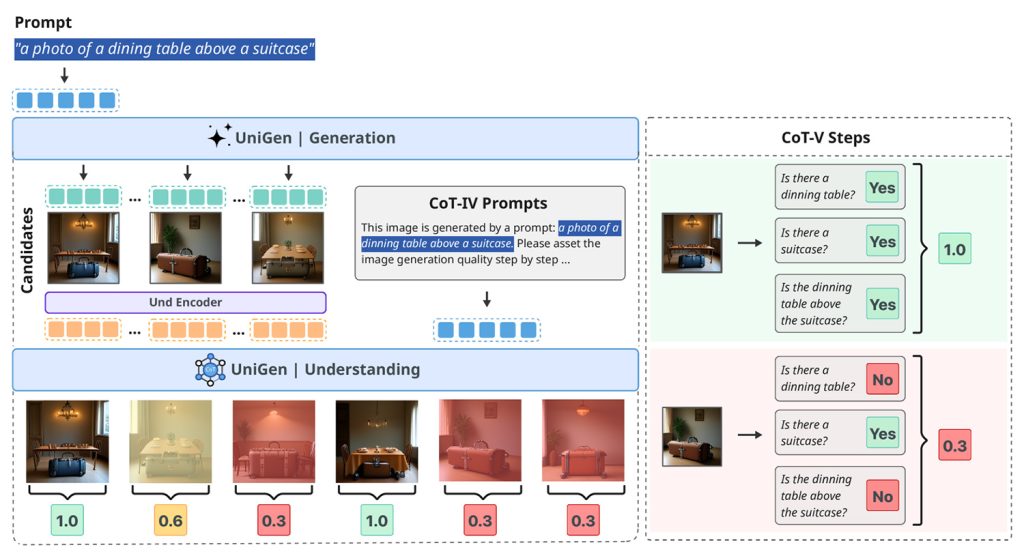
The researchers then employ reinforcement learning in a way that is arguably the most important contribution of the paper: they use the same reward system for both image generation and editing, which was previously challenging because edits can range from minor tweaks to complete transformations.
As a result, when tested on several industry-standard benchmarks that measure how well models follow instructions, maintain visual quality, and handle complex edits, UniGen-1.5 either matches or surpasses multiple state-of-the-art open and proprietary multimodal large language models:
Through the efforts above, UniGen-1.5 provides a stronger baseline for advancing research on unified MLLMs and establishes competitive performance across image understanding, generation, and editing benchmarks. The experimental results show that UniGen-1.5 obtains 0.89 and 86.83 on GenEval and DPG-Bench, significantly outperforming recent methods such as BAGEL and BLIP3o. For image editing, UniGen-1.5 achieves 4.31 overall scores on ImgEdit, surpassing recent open-sourced models such as OminiGen2 and is comparable to proprietary models such as GPT-Image-1.
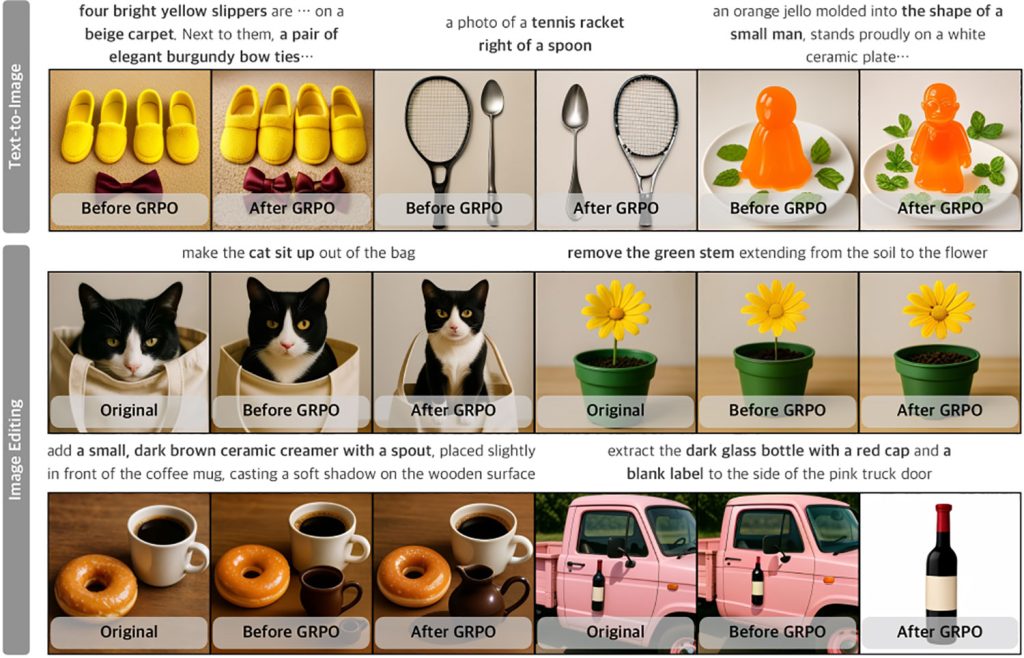
Here are some examples of text-to-image generation, and image editing capabilities of UniGen-1.5 (sadly, the researchers appear to have mistakenly cropped out the prompts for the Text-to-Image segment in the first image):

The researchers note that UniGen-1.5 struggles with text generation, as well as with identity consistence under certain circumstances:
Failure cases of UniGen-1.5 in both text-to-image generation and image editing tasks are illustrated in Figure A. In the first row, we present the instances where UniGen-1.5 fails to accurately render text characters, as the light-weight discrete detokenizer struggles to control the fine-grained structural details required for text generation. In the second row, we display two examples with visible identity shifts highlighted by the circle, e.g., the changes in cat’s facial fur texture and shape, and the differences in color of the bird’s feather. UniGen-1.5 needs further improvement to address these limitations.

You can find the full study here.
Accessory deals on Amazon
- AirPods Pro 3
- Beats USB-C to USB-C Woven Short Cable
- Wireless CarPlay adapter
- Logitech MX Master 4
- Apple AirTag 4 Pack
FTC: We use income earning auto affiliate links. More.

Comments